保護力參數設定
隱私保護力是合成資料品質評估的首要關鍵。無論合成資料的用途為何(資料釋出或特定任務建模),都必須確保其不會洩漏原始資料中的個人隱私資訊。在進行保真度或實用性評測之前,必須先確認隱私保護力達到可接受的標準。
隱私風險推估能夠量化合成資料在面對不同類型隱私攻擊時的脆弱程度,協助您根據資料敏感度與釋出範圍調整合成演算法的隱私參數、評估即使使用隱私強化技術後仍殘留的實際風險水準、滿足個資保護法規對匿名化資料的標準(如 GDPR、WP29 指引),以及向資料接收方證明合成資料的隱私保護程度。
三種隱私攻擊模式
PETsARD 使用 Anonymeter 評測工具模擬歐盟個人資料保護指令第29條工作小組 (WP29) 於 2014 年提出的三種隱私攻擊模式,並且該工具的演算法實現方式於 2023 年獲得法國國家資訊自由委員會 (CNIL) 的認可符合上述標準:
指認性風險 (Singling Out Risk)
核心問題在於評估資料中是否存在有唯一組合的一筆資料。此攻擊的目標是從資料中識別出特定個體,攻擊者試圖找出唯一具有特徵 X、Y、Z 的個體。典型的風險情境是攻擊者擁有部分個人特徵資訊,並試圖在資料集中找出該個體。
連結性風險 (Linkability Risk)
核心問題在於評估是否存在能將兩份資料關聯後,共同指向特定人的機會。此攻擊的目標是連結不同資料集中相同個體的紀錄,攻擊者試圖判斷紀錄 A 和 B 是否屬於同一人。典型的風險情境是攻擊者可存取多個資料來源,並試圖透過共同特徵連結同一個體。
推論性風險 (Inference Risk)
核心問題在於評估是否存在能推測出隱藏或未揭露的資訊。此攻擊的目標是從已知特徵推斷其他敏感屬性,攻擊者試圖推論具有特徵 X 和 Y 的人,其敏感特徵 Z 為何。典型的風險情境是攻擊者知道某種部分特徵,並試圖推論其敏感資訊。
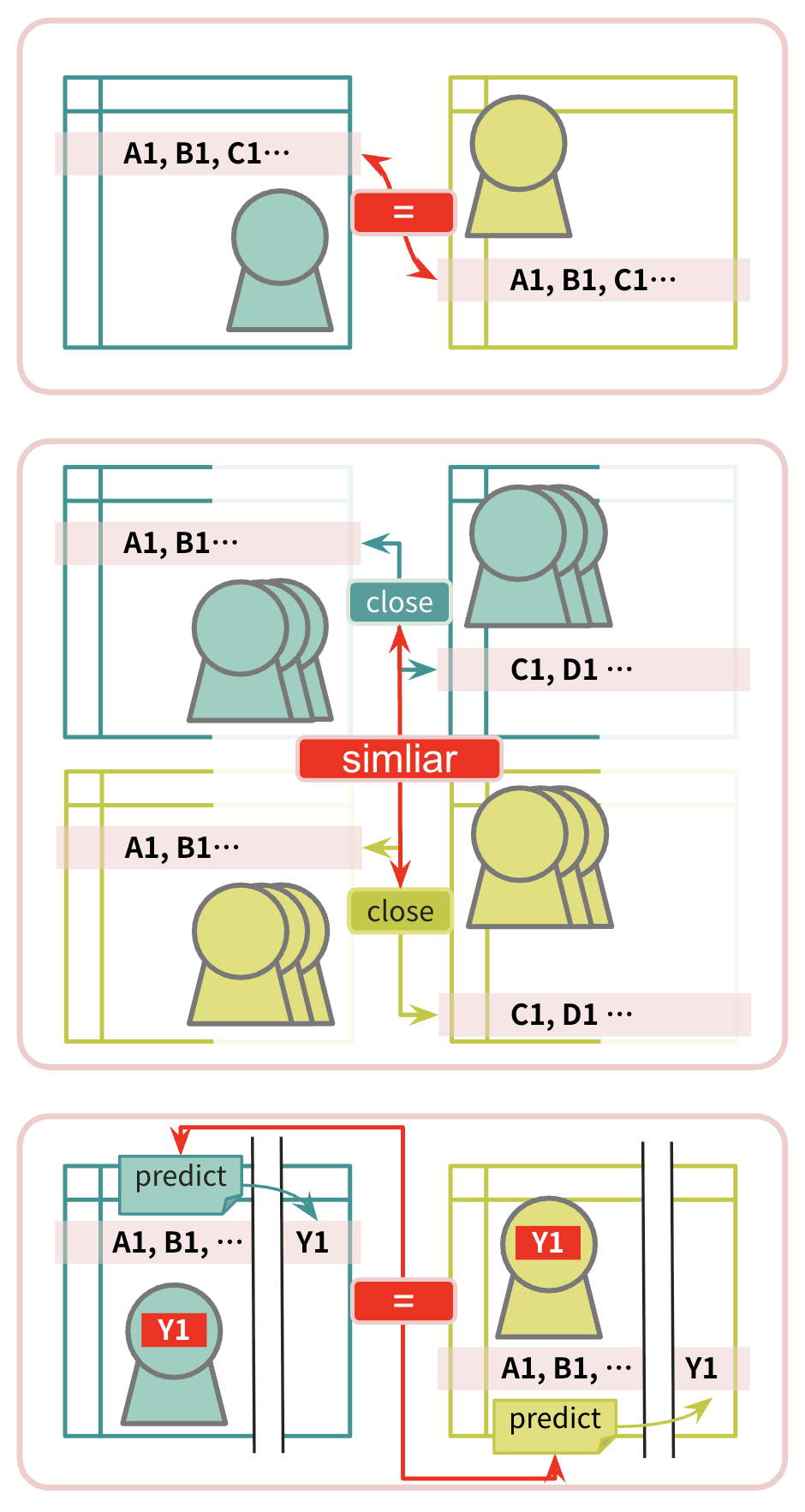
選擇適當的攻擊模式
隱私風險評測並非一體適用,應根據資料特性與使用情境選擇適當的攻擊模式進行評估。本團隊認為指認性風險評測是必要的,所有合成資料都必須通過此項評測;而連結性與推論性風險評測則可作為佐證,其是否必要測量以及欄位選擇,可由單位協同法遵部門共同決定。
指認性風險評測:必要且必須通過
指認性風險是所有合成資料都必須評測並通過的基本項目。此評測驗證資料中是否存在唯一組合,能夠輕易識別特定個體。無論資料用途或釋出範圍為何,都應確保指認性風險達標。
但 Anonymeter 的指認性攻擊實作採用反覆取出放回的方式生成攻擊查詢。當資料本身無法產生足夠多的獨特組合時,演算法並無檢查機制,仍會持續嘗試直到達到最大嘗試次數 (max_attempts),造成巨大的運算時間負擔。因此,本團隊建議手動設定參數以避免過長的運算時間:n_attacks 介於 100 到 n_rows/100 之間,而 max_attempts 可介於 1,000 到 n_rows/10 之間。
連結性風險評測:可作為佐證
連結性風險的評測需求取決於資料來源的複雜度。當資料集整合自多個來源(例如 OLAP 分析資料庫整合多個 OLTP 資料源),且各來源具有不同的個資敏感程度與資料擁有者時,應進行連結性評測以模擬攻擊者取得多份資料後的連結風險。
評測的關鍵是合理拆分輔助欄位 (aux_cols) 來模擬「散落在多個資料集的同一個人,會被合成資料跨資料集連結在一起」的攻擊情境。想像這個資料集如果要拆成兩份持分資料,從資料流程上、領域知識上、組織商業制度上,怎麼樣的拆分是最可能發生的?這種拆分應該反映實際業務中不同單位可能持有不同資料子集的情境。以保險理賠資料為例來說明拆分原則的話:
- 第一組:申請收件單位看進件即可知的資訊(如申請人基本資料、申請類型、申請日期)
- 第二組:拒賠風險單位才知道的資訊(如理賠金額、審核結果、風險評分)
相反地,若資料來源單純,或業務場景本質上不可能產生資料分持的情況,本團隊實務建議無須硬性拆分資料進行評測。
推論性風險評測:視情境與技術條件而定
推論性風險的評測需同時考量業務需求與技術可行性。首先,您必須明確定義一個「機密欄位」(secret) 作為推論目標。若缺乏充分的領域知識來認定某個欄位的確特別敏感或真的涉及脆弱族群,則不建議進行此項評測。
若資料用於分類或迴歸任務,建議使用該任務的依變數 (target variable) 作為機密欄位,若無下游任務,則以領域知識中認定最敏感的欄位(如收入、健康狀態、信用評分等)為機密欄位。
Anonymeter 的推論性演算法基於 k-近鄰 (k=1) 找出合成資料中最相似的記錄,並將該記錄的秘密值作為推論結果。對於分類型欄位使用精確匹配判定成功,對於數值型欄位則使用 5% 相對容忍度(相對誤差 ≤ 5% 視為推論成功)。因此,高基數欄位(如身分證字號,每筆資料皆不同)幾乎不可能產生匹配的推論,導致風險分數趨近於無意義的基線值,不適合進行推論性評測。
風險分數解讀
隱私風險分數的核心概念是「超額風險」(excess risk),也就是合成資料相較於隨機猜測所帶來的額外隱私洩漏。評測過程會進行兩種攻擊:主要攻擊使用合成資料作為知識庫來推測原始資料,基線攻擊則採取隨機猜測策略。若主要攻擊的成功率遠高於基線攻擊,代表合成資料確實洩漏了原始資料的資訊。
風險分數將這個差距標準化為 0 到 1 之間的數值,其中 0 代表合成資料沒有帶來任何額外風險(攻擊成功率等同隨機猜測),1 代表合成資料完全洩漏了原始資料的資訊(攻擊達到理論上的最佳效果)。分數越高,代表隱私風險越大,合成資料對原始資料的保護力越弱。
本團隊參考新加坡個人資料保護委員會 (PDPC) 於 2023 年發布的合成資料指引,建議三種攻擊模式的風險閾值皆為 risk < 0.09。此標準源自國際上對於匿名化資料的隱私保護實務,但並非絕對。若您的行業或組織對隱私保護有更嚴格的要求(例如醫療、金融領域),可採用更嚴謹的標準;反之,若您的資料敏感度較低或僅供內部使用,也可依據風險評估結果調整為較寬鬆的標準。
實際應用案例
案例 1:多來源資料整合的連結性評測
某金融機構整合了客戶基本資料、交易記錄、信用評分等來自不同部門的資料,準備釋出合成版本供外部研究使用。由於資料來源複雜,需要同時評測指認性與連結性風險:
Splitter:
external_split:
method: custom_data
filepath:
ori: benchmark://adult-income_ori
control: benchmark://adult-income_control
schema:
ori: benchmark://adult-income_schema
control: benchmark://adult-income_schema
Synthesizer:
external_data:
method: custom_data
filepath: benchmark://adult-income_syn
schema: benchmark://adult-income_schema
Evaluator:
# 指認性風險:必要評測
singling_out_risk:
method: anonymeter-singlingout
n_attacks: 100 # 根據資料規模調整
max_attempts: 1000 # 根據資料規模調整
# 連結性風險:依實際分持方式拆分欄位
linkability_risk:
method: anonymeter-linkability
max_n_attacks: true # PETsARD 自動設定為最大值
aux_cols:
- # 第一組:客戶服務部門持有
- workclass
- education
- occupation
- race
- gender
- # 第二組:風險管理部門持有
- age
- marital-status
- relationship
- native-country
- income在此案例中,連結性評測模擬了攻擊者分別從客戶服務部門和風險管理部門取得資料後,試圖將兩份資料連結起來識別特定個體的情境。所有風險分數應低於 0.09。
案例 2:特定建模任務的推論性評測
某醫療機構計劃使用合成病歷資料訓練疾病風險預測模型。由於模型的目標變數(是否罹患特定疾病)是高度敏感資訊,需要評測推論性風險:
Splitter:
external_split:
method: custom_data
filepath:
ori: benchmark://adult-income_ori
control: benchmark://adult-income_control
schema:
ori: benchmark://adult-income_schema
control: benchmark://adult-income_schema
Synthesizer:
external_data:
method: custom_data
filepath: benchmark://adult-income_syn
schema: benchmark://adult-income_schema
Evaluator:
# 指認性風險:必要評測
singling_out_risk:
method: anonymeter-singlingout
n_attacks: 100 # 根據資料規模調整
max_attempts: 1000 # 根據資料規模調整
# 推論性風險:以下游任務的依變數作為機密
inference_risk:
method: anonymeter-inference
max_n_attacks: true # PETsARD 自動設定為最大值
secret: income # 下游任務的目標變數
# aux_cols 由 PETsARD 自動設定為 secret 以外所有欄位在此案例中,推論性評測模擬了攻擊者知道病患的基本資訊和部分檢查結果,試圖推論其疾病狀態的情境。風險分數應低於 0.09。
注意事項與常見問題
處理「Reached maximum number of attempts」警告
此警告發生的原因是資料的獨特組合太少,無法產生足夠多的不同攻擊查詢。這通常發生在資料集太小、欄位的基數太低(唯一值太少),或欄位間高度相關而限制了獨特組合的數量。
面對此警告,您可以嘗試減少 n_attacks(對小資料集設定較小的值,例如 100-500)、增加 max_attempts(允許更多嘗試來找到獨特查詢,但會增加運算時間),或調整 n_cols(嘗試每次查詢使用較少的欄位,例如 2 個而非 3 個)。然而,如果警告持續出現,這實際上表示資料本質上的攻擊面有限,可能代表較好的隱私保護,此時可以接受這個限制。
主要攻擊率低於基線攻擊率的情況
當主要攻擊率 (attack_rate) ≤ 基線攻擊率 (baseline_rate) 時,評測結果不具參考價值。這種情況可能發生在攻擊次數過少而無法產生有意義的統計結果、輔助資訊 (aux_cols) 設定不足導致攻擊難度過高,或資料本身的特性使攻擊不可行。
面對這個問題,您可以嘗試增加攻擊次數 (n_attacks)、檢視並調整輔助欄位的選擇,或確認資料是否適合該類型的攻擊評測。然而,如果調整後情況仍持續出現,這實際上表示原始資料特性、尤其是值域的排列組合,對攻擊具有較強的抵抗力,可能代表較好的隱私保護,此時可以接受這個結果。
風險分數為 0.0 並不代表完全安全
Anonymeter 計算的風險僅是各攻擊模式的其中一套評測方式,0.0 並不代表完全沒有隱私風險。為避免「先收集、後解密」(HNDL, Harvest Now, Decrypt Later) 的潛在風險,使用者需對結果持保留態度,並建議結合其他保護措施來保護合成資料,例如限制資料釋出範圍、實施資料存取控制、定期審查資料使用情況,以及考慮額外的技術保護措施(如差分隱私)。
參考文獻
Article 29 Data Protection Working Party. (2014). Opinion 05/2014 on Anonymisation Techniques. 0829/14/EN WP216.
Personal Data Protection Commission Singapore. (2023). Guide on Synthetic Data Generation. https://www.pdpc.gov.sg/-/media/files/pdpc/pdf-files/other-guides/guide-on-synth-data.pdf
Giomi, M., Boenisch, F., Wehmeyer, C., & Tasnádi, B. (2023). A unified framework for quantifying privacy risk in synthetic data. Proceedings on Privacy Enhancing Technologies, 2023(2), 312-328.
Commission Nationale de l’Informatique et des Libertés (CNIL). (2023). Synthetic Data: Operational Recommendations. https://www.cnil.fr/en/synthetic-data-operational-recommendations