實驗設計挑選
當合成資料用於特定機器學習任務時,實驗設計 (Experiment Design) 決定了如何訓練和評估模型以評估合成資料的實用性。不同的實驗設計回答不同的問題,適用於不同的應用情境。
相同的合成資料使用不同的實驗設計評測,可能得到截然不同的結果。選擇適當的實驗設計能夠精確量化實用性(回答與使用情境最相關的問題)、避免誤判(防止使用不適當的評測方法導致錯誤決策)、指引優化方向(根據評測結果知道該如何改進合成資料)、以及符合標準實踐(遵循業界認可的評估框架如 NIST SP 800-188)。
兩種實驗設計策略
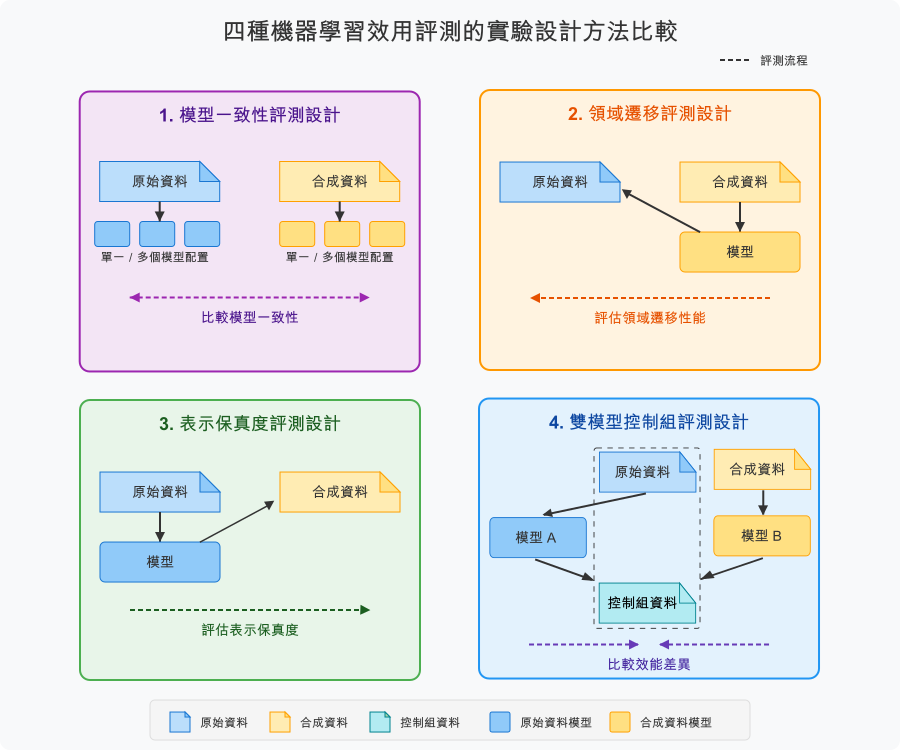
在本團隊研究得出的各種實驗設計中,PETsARD 目前支援兩種實驗設計策略:領域遷移 (Domain Transfer) 和雙模型控制組 (Dual Model Control)。
領域遷移 (Domain Transfer)
領域遷移探討「合成資料是否捕捉到能泛化到真實資料的基本模式」。在合成資料上訓練模型後在原始資料上測試,適用於模型開發和概念驗證情境。這是 PETsARD 的預設設計,因為它符合 NIST SP 800-188 對合成資料驗證的指引,並且是最常見的使用情境。
雙模型控制組 (Dual Model Control)
雙模型控制組探討「合成資料能否達到與原始資料相當的模型效能」。分別在原始和合成資料上訓練模型後在控制資料集上比較效能,適用於資料替代驗證情境。
選擇適當的實驗設計
實驗設計的選擇取決於使用情境、資料可用性、評估目的和風險容忍度。
依使用情境選擇
適合使用領域遷移的情境
在以下情境中,推薦使用領域遷移設計:
- 模型開發與驗證:評估合成資料訓練的模型能否在真實資料上表現良好
- 演算法研究:驗證新演算法在真實場景的適用性
- 資料增益預評估:檢驗合成資料是否能提供有價值的補充資訊
- 訓練資料稀缺:原始資料不足以訓練完整模型時的替代方案
判斷標準為絕對指標值(如 ROC AUC > 0.8)或模型在原始資料上的效能。
適合使用雙模型控制組的情境
在以下情境中,推薦使用雙模型控制組設計:
- 資料替代方案驗證:評估使用合成資料是否會顯著損失效能
- 隱私保護釋出評估:驗證合成資料能否達到相近的分析價值
判斷標準為兩模型效能差距小於 10% 或統計推論一致性。
依資料可用性選擇
原始資料充足
當原始資料充足可分為訓練、驗證、測試集時,兩種設計都適用,應根據使用目的選擇。
原始資料有限
當原始資料有限主要用於訓練合成器時,領域遷移較為適合,因為僅需保留少量原始資料作為測試集。相對地,雙模型控制組需要額外的控制資料集,可能不適用於資料稀缺的情境。
原始資料稀缺
當原始資料稀缺無法再取得更多時,領域遷移同樣較為適合,因為僅需保留測試集。雙模型控制組則需要訓練兩個模型,資料需求更高。
依評估目的選擇
品質檢查階段
驗證合成品質時,推薦使用領域遷移,因為可以直接評估合成資料學習到的模式是否有效。
決策評估階段
比較替代方案時,推薦使用雙模型控制組,因為可以提供清晰的效能對比。
概念驗證階段
進行探索性研究時,推薦使用領域遷移,因為更簡單快速且適合初期評估。
依風險容忍度選擇
關鍵應用(低風險容忍)
推薦使用雙模型控制組,因為可以提供更保守的效能估計。
一般應用(適中風險容忍)
推薦使用領域遷移,因為是標準做法且廣泛接受。
實驗性應用(高風險容忍)
推薦使用領域遷移搭配快速迭代,以效率為優先考量。
實際應用案例
案例 1:研究團隊的模型開發
某研究團隊希望使用合成資料開發信用風險預測模型。在模型開發完成後,將部署到真實資料上。此情境需要驗證在合成資料上訓練的模型能否泛化到真實場景:
Evaluator:
ml_utility_assessment:
method: mlutility
task_type: classification
target: income
experiment_design: domain_transfer # 領域遷移
random_state: 42評測流程包含三個步驟:
- 在合成資料上訓練模型
- 在原始資料上測試模型
- 評估模型在原始資料上的效能
成功標準要求絕對指標達標:
- ROC AUC ≥ 0.8
- F1 Score ≥ 0.7
- Precision ≥ 0.7
- Recall ≥ 0.7
案例 2:政府機構的資料替代驗證
某政府機構考慮釋出合成版本的調查資料供研究使用,需要驗證使用合成資料進行分析是否會得到與原始資料相近的結論:
Evaluator:
ml_utility_assessment:
method: mlutility
task_type: classification
target: income
experiment_design: dual_model_control # 雙模型控制組
random_state: 42評測流程包含四個步驟:
- 在原始資料上訓練模型 A
- 在合成資料上訓練模型 B
- 在控制資料集(保留集)上測試兩個模型
- 比較兩個模型的效能差距
成功標準要求效能差距小,一般標準為指標差距小於 10%。
注意事項與常見問題
實驗設計是否影響隱私風險?
實驗設計本身不影響隱私風險,但評測流程中的資料使用方式可能有影響。
領域遷移需要使用原始資料作為測試集,因此在架構上存在合成資料與原始資料接觸的隱私考量。雖然測試階段無訓練過程風險相對較低,但仍需確保原始測試資料的安全存取。
雙模型控制組同樣需要將原始資料再切出額外的控制資料集用於測試,控制資料集的保護應與原始資料同等重要。
無論選擇哪種實驗設計,都應該:
- 在實用性評估之前完成隱私保護力評估
- 確保所有原始資料(訓練、測試、控制)都受到適當保護
- 評測環境與生產環境隔離
- 記錄所有資料存取和使用記錄
兩種設計的結果可以互相比較嗎?
不可以直接比較,因為它們回答不同的問題。
領域遷移探討「合成資料訓練的模型在真實資料上表現如何」,提供絕對指標值(如 ROC AUC = 0.82)。雙模型控制組探討「合成資料與原始資料訓練的模型效能差距多大」,提供相對差距(如差距 = 5.9%)。
正確做法是:
- 根據使用目的選擇一種設計
- 使用該設計的標準評估結果
- 不要混用兩種設計的結果進行比較
常見的錯誤問法:「領域遷移得到 AUC 0.82,雙模型控制組差距 5%,哪個更好?」
正確的問法應該是:「我的使用情境需要領域遷移還是雙模型控制組?」
資料不平衡時如何選擇?
兩種設計都適用於資料不平衡的情境。PETsARD 提供重採樣方法如 SMOTE-ENN 和 SMOTE-Tomek,在設定不平衡分類評測時:
- 使用 mlutility 方法並指定不平衡目標欄位
- 評估時特別關注 MCC 和 PR AUC 指標
- 這些指標對不平衡資料更為穩健
無論選擇哪種實驗設計,關鍵都在於使用適當的評測指標來反映真實的模型效能。
參考文獻
NIST SP 800-188. (2023). De-Identifying Government Data Sets. Section 4.4.5 “Synthetic Data with Validation”
Yoon, J., Drumright, L. N., & van der Schaar, M. (2020). Anonymization through data synthesis using generative adversarial networks (ADS-GAN). IEEE Journal of Biomedical and Health Informatics, 24(8), 2378-2388.
Xu, L., Skoularidou, M., Cuesta-Infante, A., & Veeramachaneni, K. (2019). Modeling tabular data using conditional GAN. Advances in Neural Information Processing Systems, 32.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 27.