Protection Parameter Configuration
Privacy protection is the primary key to synthetic data quality assessment. Regardless of the intended use of synthetic data (data release or specific task modeling), it must ensure that it does not leak personally identifiable information from the original data. Before conducting fidelity or utility evaluations, privacy protection must first be confirmed to meet acceptable standards.
Privacy risk estimation can quantify the vulnerability of synthetic data when facing different types of privacy attacks, helping you adjust privacy parameters of synthesis algorithms based on data sensitivity and release scope, assess actual risk levels that remain even after using privacy-enhancing technologies, meet standards for anonymized data under data protection regulations (such as GDPR, WP29 guidelines), and demonstrate the degree of privacy protection of synthetic data to data recipients.
Three Privacy Attack Modes
PETsARD uses the Anonymeter evaluation tool to simulate three privacy attack modes proposed by the Article 29 Data Protection Working Party (WP29) in 2014, and the tool’s algorithm implementation was recognized by the French National Commission on Informatics and Liberty (CNIL) in 2023 as compliant with these standards:
Singling Out Risk
The core issue is to assess whether there exists a unique combination of a single record in the data. The goal of this attack is to identify specific individuals from the data, where attackers attempt to find individuals uniquely characterized by features X, Y, Z. A typical risk scenario is when attackers possess partial personal characteristic information and attempt to locate that individual in the dataset.
Linkability Risk
The core issue is to assess whether there is an opportunity to link two pieces of data together to jointly point to a specific person. The goal of this attack is to link records of the same individual across different datasets, where attackers attempt to determine whether records A and B belong to the same person. A typical risk scenario is when attackers can access multiple data sources and attempt to link the same individual through common characteristics.
Inference Risk
The core issue is to assess whether there exists the ability to infer hidden or undisclosed information. The goal of this attack is to infer other sensitive attributes from known characteristics, where attackers attempt to deduce what sensitive feature Z is for a person with features X and Y. A typical risk scenario is when attackers know certain partial characteristics and attempt to infer sensitive information.
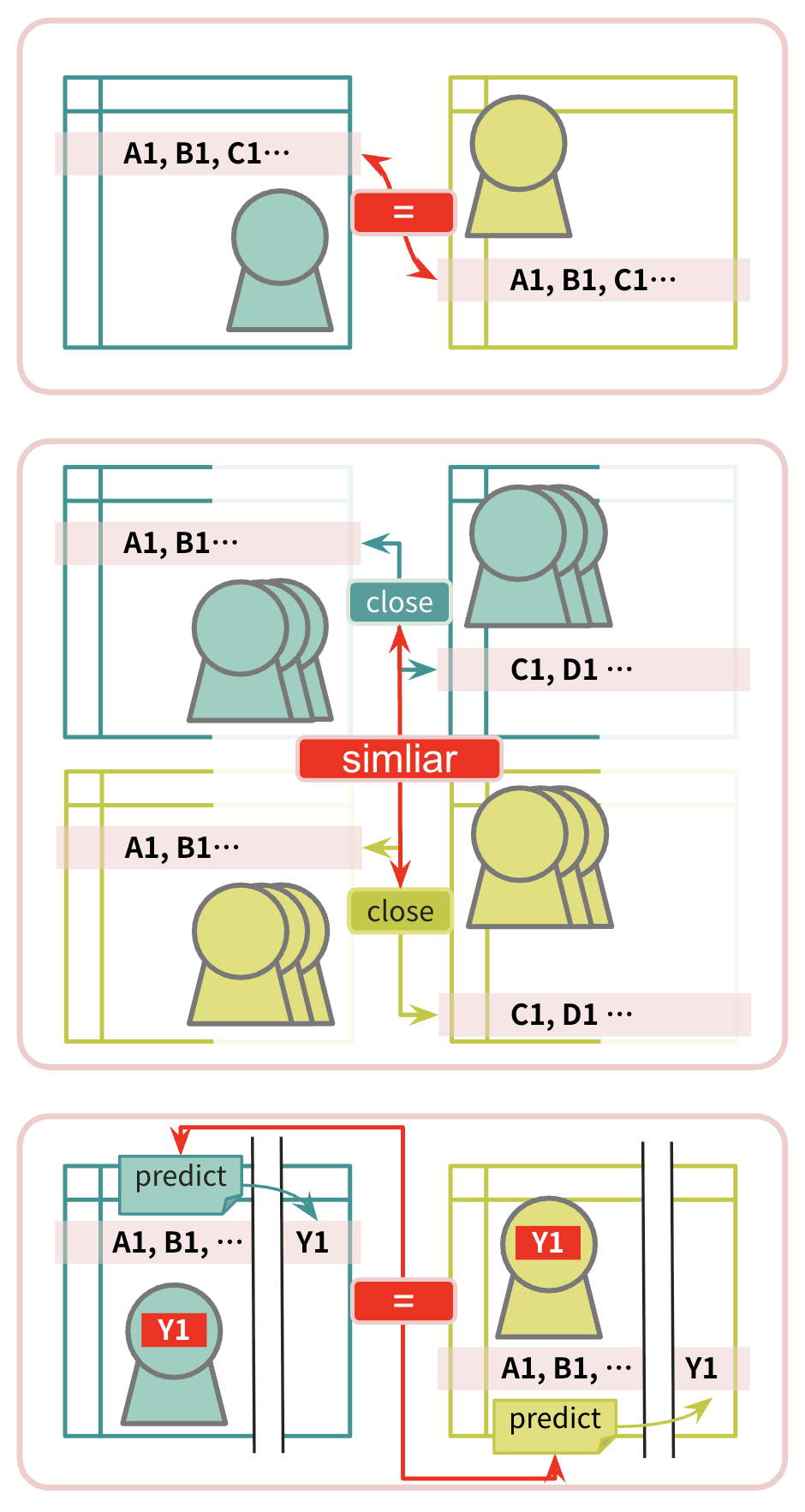
Selecting Appropriate Attack Modes
Privacy risk evaluation is not one-size-fits-all and should select appropriate attack modes based on data characteristics and usage scenarios. Our team believes that singling out risk evaluation is necessary, and all synthetic data must pass this evaluation; while linkability and inference risk evaluations can serve as corroboration, and whether they need to be measured and which columns to select can be jointly determined by the unit and the compliance department.
Singling Out Risk Evaluation: Necessary and Must Pass
Singling out risk is a basic item that all synthetic data must evaluate and pass. This evaluation verifies whether there are unique combinations in the data that can easily identify specific individuals. Regardless of data purpose or release scope, singling out risk should be ensured to meet standards.
However, Anonymeter’s singling out attack implementation uses a sampling with replacement approach to generate attack queries. When the data itself cannot generate enough unique combinations, the algorithm has no checking mechanism and will continue attempting until reaching the maximum number of attempts (max_attempts), causing enormous computational time burden. Therefore, our team recommends manually setting parameters to avoid excessively long computation times: n_attacks between 100 and n_rows/100, while max_attempts can be between 1,000 and n_rows/10.
Linkability Risk Evaluation: Can Serve as Corroboration
The evaluation need for linkability risk depends on the complexity of data sources. When datasets are integrated from multiple sources (e.g., OLAP analytical databases integrating multiple OLTP data sources), and each source has different levels of personal information sensitivity and data owners, linkability evaluation should be conducted to simulate the linkage risk after attackers obtain multiple pieces of data.
The key to evaluation is to reasonably split auxiliary columns (aux_cols) to simulate the attack scenario of “the same person scattered across multiple datasets being linked across datasets by synthetic data.” Imagine how this dataset would most likely be split into two partial datasets from the data flow, domain knowledge, and organizational business system perspectives. This split should reflect scenarios where different units in actual business might hold different data subsets. Taking insurance claim data as an example to illustrate splitting principles:
- First Group: Information known by the application receiving unit upon intake (such as applicant basic information, application type, application date)
- Second Group: Information known only by the rejection risk unit (such as claim amount, review results, risk score)
Conversely, if the data source is simple, or the business scenario inherently cannot produce data partitioning situations, our team’s practical recommendation is that there is no need to forcibly split data for evaluation.
Inference Risk Evaluation: Depends on Scenario and Technical Conditions
Inference risk evaluation must consider both business needs and technical feasibility. First, you must clearly define a “secret” column as the inference target. If there is insufficient domain knowledge to determine that a column is particularly sensitive or truly involves vulnerable groups, this evaluation is not recommended.
If data is used for classification or regression tasks, it is recommended to use the target variable of that task as the secret column. If there is no downstream task, use the column considered most sensitive in domain knowledge (such as income, health status, credit score, etc.) as the secret column.
Anonymeter’s inference algorithm is based on k-nearest neighbors (k=1) to find the most similar record in synthetic data and uses that record’s secret value as the inference result. For categorical columns, it uses exact matching to determine success, while for numerical columns, it uses 5% relative tolerance (relative error ≤ 5% is considered successful inference). Therefore, high-cardinality columns (such as ID numbers, where each record is different) are almost impossible to produce matching inferences, leading to risk scores approaching meaningless baseline values, making them unsuitable for inference risk evaluation.
Risk Score Interpretation
The core concept of privacy risk score is “excess risk,” which is the additional privacy leakage brought by synthetic data compared to random guessing. The evaluation process conducts two types of attacks: the main attack uses synthetic data as a knowledge base to infer original data, while the baseline attack adopts a random guessing strategy. If the success rate of the main attack is much higher than the baseline attack, it indicates that synthetic data indeed leaks information from the original data.
The risk score normalizes this difference to a value between 0 and 1, where 0 represents that synthetic data brings no additional risk (attack success rate equals random guessing), and 1 represents that synthetic data completely leaks original data information (attack achieves theoretically optimal effect). The higher the score, the greater the privacy risk and the weaker the protection of synthetic data for original data.
Our team refers to the synthetic data guidance released by Singapore’s Personal Data Protection Commission (PDPC) in 2023, recommending that the risk threshold for all three attack modes should be risk < 0.09. This standard originates from international privacy protection practices for anonymized data but is not absolute. If your industry or organization has stricter requirements for privacy protection (such as healthcare, financial sectors), more stringent standards can be adopted; conversely, if your data sensitivity is lower or is only for internal use, more relaxed standards can be adjusted based on risk assessment results.
Practical Application Cases
Case 1: Linkability Evaluation for Multi-Source Data Integration
A financial institution integrated customer basic information, transaction records, credit scores, and other data from different departments, preparing to release a synthetic version for external research use. Due to the complex data sources, both singling out and linkability risk evaluations need to be conducted:
Splitter:
external_split:
method: custom_data
filepath:
ori: benchmark://adult-income_ori
control: benchmark://adult-income_control
schema:
ori: benchmark://adult-income_schema
control: benchmark://adult-income_schema
Synthesizer:
external_data:
method: custom_data
filepath: benchmark://adult-income_syn
schema: benchmark://adult-income_schema
Evaluator:
# Singling out risk: mandatory evaluation
singling_out_risk:
method: anonymeter-singlingout
n_attacks: 100 # Adjust based on data scale
max_attempts: 1000 # Adjust based on data scale
# Linkability risk: split columns according to actual data partitioning
linkability_risk:
method: anonymeter-linkability
max_n_attacks: true # PETsARD automatically sets to maximum value
aux_cols:
- # First group: held by customer service department
- workclass
- education
- occupation
- race
- gender
- # Second group: held by risk management department
- age
- marital-status
- relationship
- native-country
- incomeIn this case, linkability evaluation simulates the scenario where attackers obtain data separately from the customer service department and risk management department, then attempt to link the two pieces of data to identify specific individuals. All risk scores should be below 0.09.
Case 2: Inference Risk Evaluation for Specific Modeling Tasks
A medical institution plans to use synthetic medical record data to train a disease risk prediction model. Since the model’s target variable (whether suffering from a specific disease) is highly sensitive information, inference risk evaluation is needed:
Splitter:
external_split:
method: custom_data
filepath:
ori: benchmark://adult-income_ori
control: benchmark://adult-income_control
schema:
ori: benchmark://adult-income_schema
control: benchmark://adult-income_schema
Synthesizer:
external_data:
method: custom_data
filepath: benchmark://adult-income_syn
schema: benchmark://adult-income_schema
Evaluator:
# Singling out risk: mandatory evaluation
singling_out_risk:
method: anonymeter-singlingout
n_attacks: 100 # Adjust based on data scale
max_attempts: 1000 # Adjust based on data scale
# Inference risk: use downstream task's dependent variable as secret
inference_risk:
method: anonymeter-inference
max_n_attacks: true # PETsARD automatically sets to maximum value
secret: income # Target variable of downstream task
# aux_cols automatically set by PETsARD to all columns except secretIn this case, inference risk evaluation simulates the scenario where attackers know a patient’s basic information and some test results, attempting to infer their disease status. The risk score should be below 0.09.
Notes and Common Questions
Handling “Reached maximum number of attempts” Warning
This warning occurs because the data has too few unique combinations to generate enough different attack queries. This typically happens when the dataset is too small, columns have low cardinality (too few unique values), or columns are highly correlated, limiting the number of unique combinations.
When facing this warning, you can try reducing n_attacks (set smaller values for small datasets, e.g., 100-500), increasing max_attempts (allow more attempts to find unique queries, but will increase computation time), or adjusting n_cols (try using fewer columns per query, e.g., 2 instead of 3). However, if the warning persists, this actually indicates that the data inherently has a limited attack surface, which may represent better privacy protection, and this limitation can be accepted.
When Main Attack Rate is Lower Than Baseline Attack Rate
When main attack rate (attack_rate) ≤ baseline attack rate (baseline_rate), the evaluation results have no reference value. This situation may occur when the number of attacks is too small to produce meaningful statistical results, auxiliary information (aux_cols) settings are insufficient leading to excessively high attack difficulty, or data characteristics make attacks infeasible.
Facing this problem, you can try increasing the number of attacks (n_attacks), reviewing and adjusting auxiliary column selections, or confirming whether the data is suitable for this type of attack evaluation. However, if the situation persists after adjustment, this actually indicates that the original data characteristics, especially the permutations and combinations of value domains, have strong resistance to attacks, which may represent better privacy protection, and this result can be accepted.
Risk Score of 0.0 Does Not Mean Complete Safety
The risk calculated by Anonymeter is just one set of evaluation methods for each attack mode; 0.0 does not represent complete absence of privacy risk. To avoid potential “Harvest Now, Decrypt Later” (HNDL) risks, users need to maintain a reserved attitude toward results and are advised to combine other protective measures to protect synthetic data, such as limiting data release scope, implementing data access control, regularly reviewing data usage, and considering additional technical protective measures (such as differential privacy).
References
Article 29 Data Protection Working Party. (2014). Opinion 05/2014 on Anonymisation Techniques. 0829/14/EN WP216.
Personal Data Protection Commission Singapore. (2023). Guide on Synthetic Data Generation. https://www.pdpc.gov.sg/-/media/files/pdpc/pdf-files/other-guides/guide-on-synth-data.pdf
Giomi, M., Boenisch, F., Wehmeyer, C., & Tasnádi, B. (2023). A unified framework for quantifying privacy risk in synthetic data. Proceedings on Privacy Enhancing Technologies, 2023(2), 312-328.
Commission Nationale de l’Informatique et des Libertés (CNIL). (2023). Synthetic Data: Operational Recommendations. https://www.cnil.fr/en/synthetic-data-operational-recommendations