Experiment Design Selection
When synthetic data is used for specific machine learning tasks, experiment design determines how to train and evaluate models to assess the utility of synthetic data. Different experiment designs answer different questions and are suitable for different application scenarios.
The same synthetic data evaluated using different experiment designs may yield vastly different results. Selecting appropriate experiment design can accurately quantify utility (answer questions most relevant to usage scenarios), avoid misjudgment (prevent wrong decisions from using inappropriate evaluation methods), guide optimization direction (know how to improve synthetic data based on evaluation results), and comply with standard practices (follow industry-recognized evaluation frameworks such as NIST SP 800-188).
Two Experiment Design Strategies
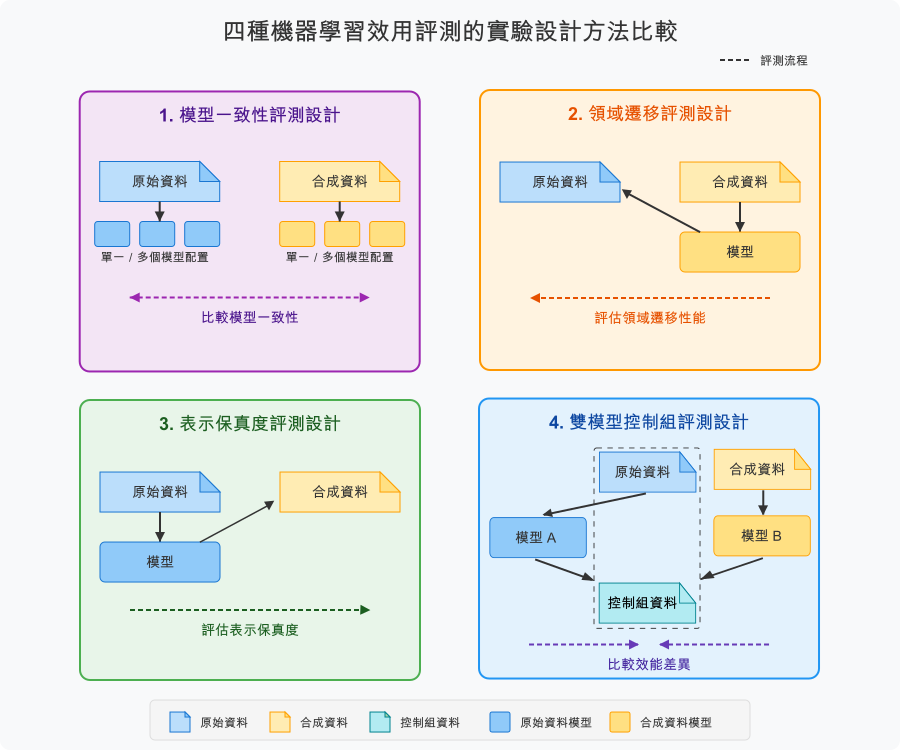
Among various experiment designs developed by our team’s research, PETsARD currently supports two experiment design strategies: Domain Transfer and Dual Model Control.
Domain Transfer
Domain transfer explores “whether synthetic data captures basic patterns that can generalize to real data.” After training a model on synthetic data, it is tested on original data, suitable for model development and proof-of-concept scenarios. This is PETsARD’s default design, as it complies with NIST SP 800-188 guidance for synthetic data validation and is the most common usage scenario.
Dual Model Control
Dual model control explores “whether synthetic data can achieve model performance comparable to original data.” After training models separately on original and synthetic data, performance is compared on a control dataset, suitable for data substitution verification scenarios.
Selecting Appropriate Experiment Design
The choice of experiment design depends on usage scenario, data availability, evaluation purpose, and risk tolerance.
Selection Based on Usage Scenario
Scenarios Suitable for Domain Transfer
Domain transfer design is recommended in the following scenarios:
- Model Development and Verification: Assess whether models trained on synthetic data can perform well on real data
- Algorithm Research: Verify applicability of new algorithms in real scenarios
- Data Augmentation Pre-evaluation: Check whether synthetic data can provide valuable supplementary information
- Training Data Scarcity: Alternative solution when original data is insufficient to train complete models
Judgment criteria are absolute metric values (such as ROC AUC > 0.8) or model performance on original data.
Scenarios Suitable for Dual Model Control
Dual model control design is recommended in the following scenarios:
- Data Substitution Verification: Assess whether using synthetic data will result in significant performance loss
- Privacy Protection Release Evaluation: Verify whether synthetic data can achieve comparable analytical value
Judgment criteria are that performance difference between two models is less than 10% or statistical inference consistency.
Selection Based on Data Availability
Sufficient Original Data
When original data is sufficient to be divided into training, validation, and test sets, both designs are applicable and should be chosen based on usage purpose.
Limited Original Data
When original data is limited and mainly used for training synthesizers, domain transfer is more suitable because it only needs to reserve a small amount of original data as test set. In contrast, dual model control requires an additional control dataset, which may not be suitable for data-scarce scenarios.
Scarce Original Data
When original data is scarce and no more can be obtained, domain transfer is similarly more suitable because it only needs to reserve a test set. Dual model control requires training two models, with higher data requirements.
Selection Based on Evaluation Purpose
Quality Check Phase
When verifying synthesis quality, domain transfer is recommended because it can directly assess whether patterns learned by synthetic data are effective.
Decision Assessment Phase
When comparing alternative solutions, dual model control is recommended because it can provide clear performance comparison.
Proof of Concept Phase
When conducting exploratory research, domain transfer is recommended because it is simpler, faster, and suitable for initial evaluation.
Selection Based on Risk Tolerance
Critical Applications (Low Risk Tolerance)
Dual model control is recommended because it can provide more conservative performance estimates.
General Applications (Moderate Risk Tolerance)
Domain transfer is recommended because it is standard practice and widely accepted.
Experimental Applications (High Risk Tolerance)
Domain transfer with rapid iteration is recommended, with efficiency as priority consideration.
Practical Application Cases
Case 1: Research Team Model Development
A research team wishes to use synthetic data to develop a credit risk prediction model. After model development is complete, it will be deployed on real data. This scenario needs to verify whether models trained on synthetic data can generalize to real scenarios:
Evaluator:
ml_utility_assessment:
method: mlutility
task_type: classification
target: income
experiment_design: domain_transfer # Domain transfer
random_state: 42The evaluation process includes three steps:
- Train model on synthetic data
- Test model on original data
- Evaluate model performance on original data
Success criteria require absolute metrics to meet standards:
- ROC AUC ≥ 0.8
- F1 Score ≥ 0.7
- Precision ≥ 0.7
- Recall ≥ 0.7
Case 2: Government Agency Data Substitution Verification
A government agency considers releasing a synthetic version of survey data for research use, needing to verify whether analyses using synthetic data will yield conclusions similar to original data:
Evaluator:
ml_utility_assessment:
method: mlutility
task_type: classification
target: income
experiment_design: dual_model_control # Dual model control
random_state: 42The evaluation process includes four steps:
- Train model A on original data
- Train model B on synthetic data
- Test both models on control dataset (holdout set)
- Compare performance difference between two models
Success criteria require small performance difference, with general standard being metric difference less than 10%.
Notes and Common Questions
Does Experiment Design Affect Privacy Risk?
Experiment design itself does not affect privacy risk, but the way data is used in the evaluation process may have an impact.
Domain transfer requires using original data as test set, so there are privacy considerations in architecture where synthetic data contacts original data. Although testing phase has no training process and risk is relatively low, secure access to original test data still needs to be ensured.
Dual model control similarly requires cutting out additional control dataset from original data for testing, and protection of control dataset should be equally important as original data.
Regardless of which experiment design is chosen, you should:
- Complete privacy protection evaluation before utility evaluation
- Ensure all original data (training, testing, control) is appropriately protected
- Isolate evaluation environment from production environment
- Record all data access and usage
Can Results from Two Designs Be Compared?
No, they cannot be directly compared because they answer different questions.
Domain transfer explores “how does a model trained on synthetic data perform on real data,” providing absolute metric values (such as ROC AUC = 0.82). Dual model control explores “how large is the performance difference between models trained on synthetic versus original data,” providing relative difference (such as difference = 5.9%).
The correct approach is:
- Choose one design based on usage purpose
- Use that design’s standard evaluation results
- Do not mix results from two designs for comparison
Common wrong question: “Domain transfer got AUC 0.82, dual model control difference is 5%, which is better?”
Correct question should be: “Does my usage scenario need domain transfer or dual model control?”
How to Choose When Data Is Imbalanced?
Both designs are suitable for imbalanced data scenarios. PETsARD provides resampling methods such as SMOTE-ENN and SMOTE-Tomek. When setting up imbalanced classification evaluation:
- Use mlutility method and specify imbalanced target column
- Pay special attention to MCC and PR AUC metrics during evaluation
- These metrics are more robust for imbalanced data
Regardless of which experiment design is chosen, the key is to use appropriate evaluation metrics to reflect true model performance.
References
NIST SP 800-188. (2023). De-Identifying Government Data Sets. Section 4.4.5 “Synthetic Data with Validation”
Yoon, J., Drumright, L. N., & van der Schaar, M. (2020). Anonymization through data synthesis using generative adversarial networks (ADS-GAN). IEEE Journal of Biomedical and Health Informatics, 24(8), 2378-2388.
Xu, L., Skoularidou, M., Cuesta-Infante, A., & Veeramachaneni, K. (2019). Modeling tabular data using conditional GAN. Advances in Neural Information Processing Systems, 32.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 27.